



一、声明
本文为学习笔记,转载请标明原文链接、作者、参考博文链接。
二、glusterfs简介
1.glusterfs简介
GlusterFS是一种可扩展的网络文件系统,适用于数据密集型任务,如云存储和媒体流。GlusterFS是免费的开源软件,可以使用常见的现成硬件。要了解更多信息,请查看Gluster项目主页。
2.gluseter架构
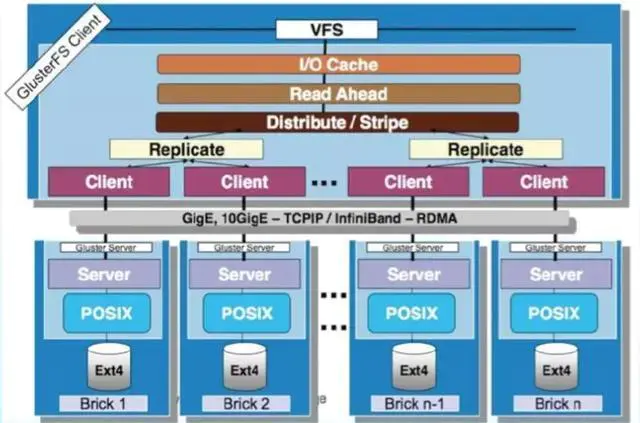
3.glustefs常用术语(摘自zzulp博客)
Brick:GFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识,如’SERVER:EXPORT’
Client: 挂载了GFS卷的设备
FUSE:Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码。通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接。
Node:一个拥有若干brick的设备
RDMA:远程直接内存访问,支持不通过双方的OS进行直接内存访问。
Self-heal:用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。
Split-brain:脑裂
Translator:
Volfile:glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname
Volume:一组bricks的逻辑集合
4.glusterfs主要模块
gluster:是cli命令执行工具,主要功能是解析命令行参数,然后把命令发送给glusterd模块执行。
glusterd:是一个管理模块,处理gluster发过来的命令,处理集群管理、存储池管理、brick管理、负载均衡、快照管理等。集群信息、存储池信息和快照信息等都是以配置文件的形式存放在服务器中,当客户端挂载存储时,glusterd会把存储池的配置文件发送给客户端。
glusterfsd:是服务端模块,存储池中的每个brick都会启动一个glusterfsd进程。此模块主要是处理客户端的读写请求,从关联的brick所在磁盘中读写数据,然后返回给客户端。
glusterfs:是客户端模块,负责通过mount挂载集群中某台服务器的存储池,以目录的形式呈现给用户。当用户从此目录读写数据时,客户端根据从glusterd模块获取的存储池的配置文件信息,通过DHT算法计算文件所在服务器的brick位置,然后通过Infiniband RDMA 或Tcp/Ip 方式把数据发送给brick,等brick处理完,给用户返回结果。存储池的副本、条带、hash、EC等逻辑都在客户端处理。
5.glusterfs的卷支持
5.1 Distributed Glusterfs Volume
分布式卷,不指定类型的话,默认创建的卷类型。分布式卷中,文件只保存一份,只会存放到一个brick上面,没有备份。这种卷是为了方便且廉价的扩展卷的大小。
不推荐单独使用此卷,此卷主要是配合复制卷使用。
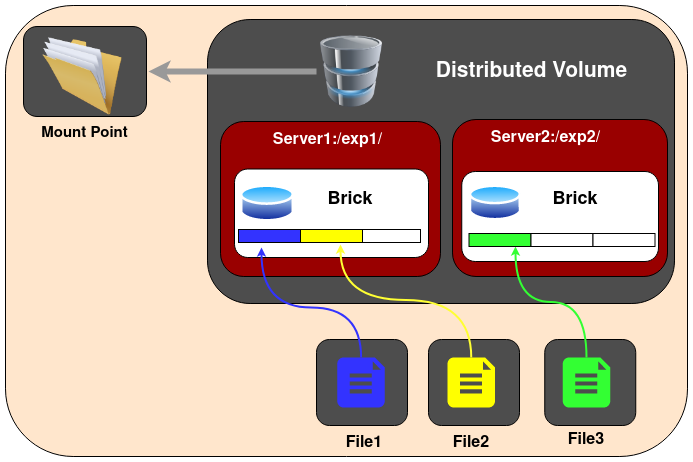
Create a Distributed Volume
gluster volume create NEW-VOLNAME [transport [tcp | rdma | tcp,rdma]] NEW-BRICK...
For example to create a distributed volume with four storage servers using TCP.
# gluster volume create test-volume server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 volume create: test-volume: success: please start the volume to access data
5.2 Replicated Glusterfs Volume
复制卷,一个文件会保存在多个brick上面。具体存储几份,依照创建卷是设置的副本卷数来决定。最少需要两个brick创建一个两个副本的卷。
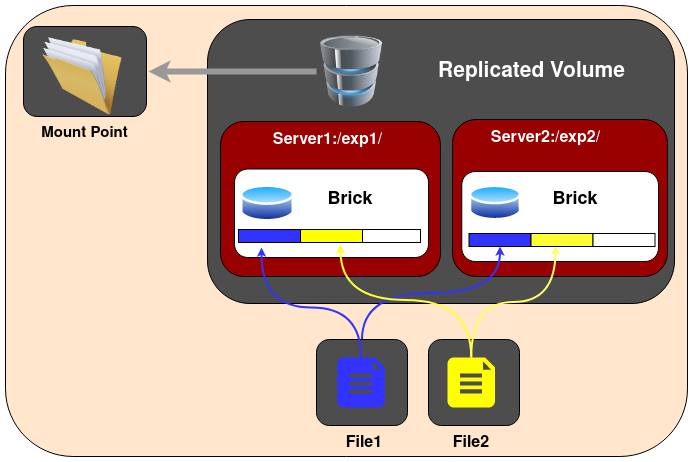
Create a Replicated Volume
gluster volume create NEW-VOLNAME [replica COUNT] [transport [tcp |rdma | tcp,rdma]] NEW-BRICK...
For example, to create a replicated volume with three storage servers:
# gluster volume create test-volume replica 3 transport tcp \
server1:/exp1 server2:/exp2 server3:/exp3
volume create: test-volume: success: please start the volume to access data
5.3 Distributed Replicated Glusterfs Volume
分布式复制卷 是把分布式卷和复制卷结合起来的一个卷。
当由于冗余和可伸缩存储而需要数据的高可用性时,使用这种卷。
所以,如果有8个砖块,副本数为2,那么前两个砖块会成为彼此的副本,然后是接下来的两个,以此类推。这个体积表示为4×2。类似地,如果有8块砖,复制数为4,那么4块砖相互复制,我们将这个体积表示为2×4体积。
注意: 1.brick的数量必需是副本数的倍数。 2.相邻的brick会成为彼此的副本。
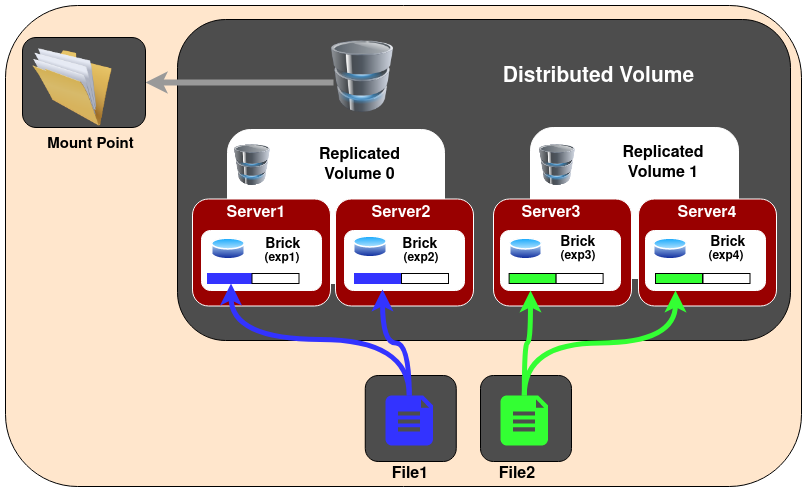
Create a Replicated Volume
gluster volume create NEW-VOLNAME [replica COUNT] [transport [tcp |rdma | tcp,rdma]] NEW-BRICK...
For example, to create a replicated volume with three storage servers:
# gluster volume create test-volume replica 3 transport tcp \
server1:/exp1 server2:/exp2 server3:/exp3
volume create: test-volume: success: please start the volume to access data
5.4 Dispersed Glusterfs Volume
分散的Glusterfs卷—分散的卷基于erasure code。它对文件的编码数据进行条纹处理,并添加了一些冗余,跨越卷中的多个块。您可以使用分散的卷来获得可配置的可靠性级别,同时减少空间浪费。卷中冗余块的数量可以由客户机在创建卷时决定。冗余砖块决定了在不中断容量操作的情况下可以丢失多少砖块。
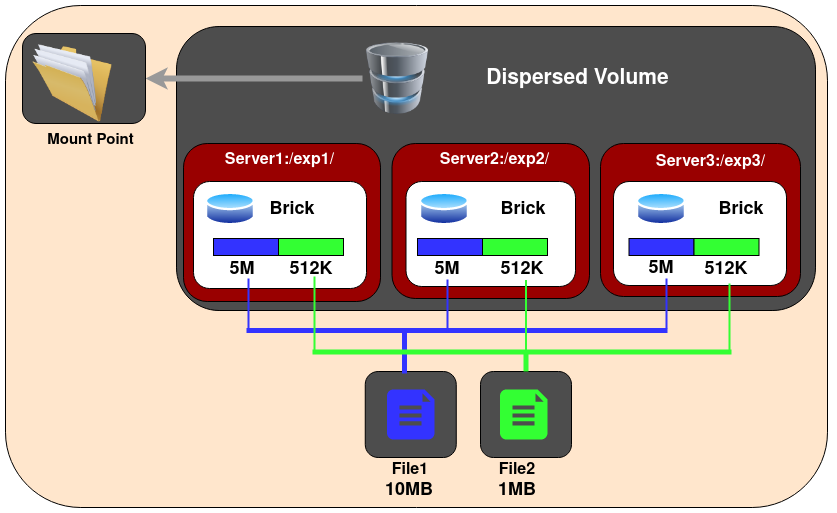
Create a dispersed volume:
# gluster volume create test-volume [disperse [<COUNT>]] [disperse-data <COUNT>] [redundancy <COUNT>] [transport tcp | rdma | tcp,rdma] <NEW-BRICK>
For example, three node dispersed volume with level of redundancy 1, (2 + 1):
# gluster volume create test-volume disperse 3 redundancy 1 server1:/exp1 server2:/exp2 server3:/exp3 volume create: test-volume: success: please start the volume to access data
5.5 Distributed Dispersed Glusterfs Volume
Distributed dispersed volumes are the equivalent to distributed replicated volumes, but using dispersed subvolumes instead of replicated ones. The number of bricks must be a multiple of the 1st subvol. The purpose for such a volume is to easily scale the volume size and distribute the load across various bricks.
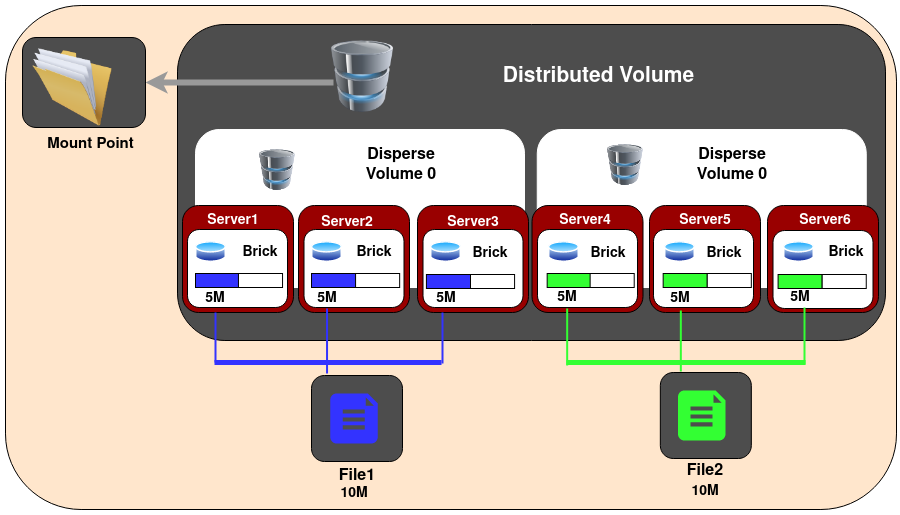
Create a dispersed volume:
# gluster volume create test-volume [disperse [<COUNT>]] [disperse-data <COUNT>] [redundancy <COUNT>] [transport tcp | rdma | tcp,rdma] <NEW-BRICK>
For example, three node dispersed volume with level of redundancy 1, (2 + 1):
# gluster volume create test-volume disperse 3 redundancy 1 server1:/exp1 server2:/exp2 server3:/exp3 volume create: test-volume: success: please start the volume to access data




